Habe mich mit der Synchronisation in Mehrträgersystemen beschäftigt.
Und habe mich damit beschäftigt ein Verfahren selbst in C++ für GnuRadio zu implementieren.
Aber erst einmal: was sind Mehträgerubertragungssysteme und was muss man bei denen synchronisieren?
Mehrträgersysteme versuchen Übertragungen über frequenzselektive Kanäle zu verbessern.
Es wird in kauf genommen, dass einzelne Träger durch den Kanal beschädigt werden können.
Um trotzdem fehlerfreie Kommunikation zu gewährleisten wird durch Kodierung redundanz über die Träger verteilt.
Der Ausfall einzelner Träger kann somit kompensiert werden.
Ein verbreitetes und einfaches Mehrträgerübertragungsverfahren is OFDM.
Um die Anforderungen eines Mehrträgersystems besser verstehen zu können stelle ich die Grundzüge von OFDM vor.
Es wird stark vereinfach
OFDM betrachtet von ganz weit weg
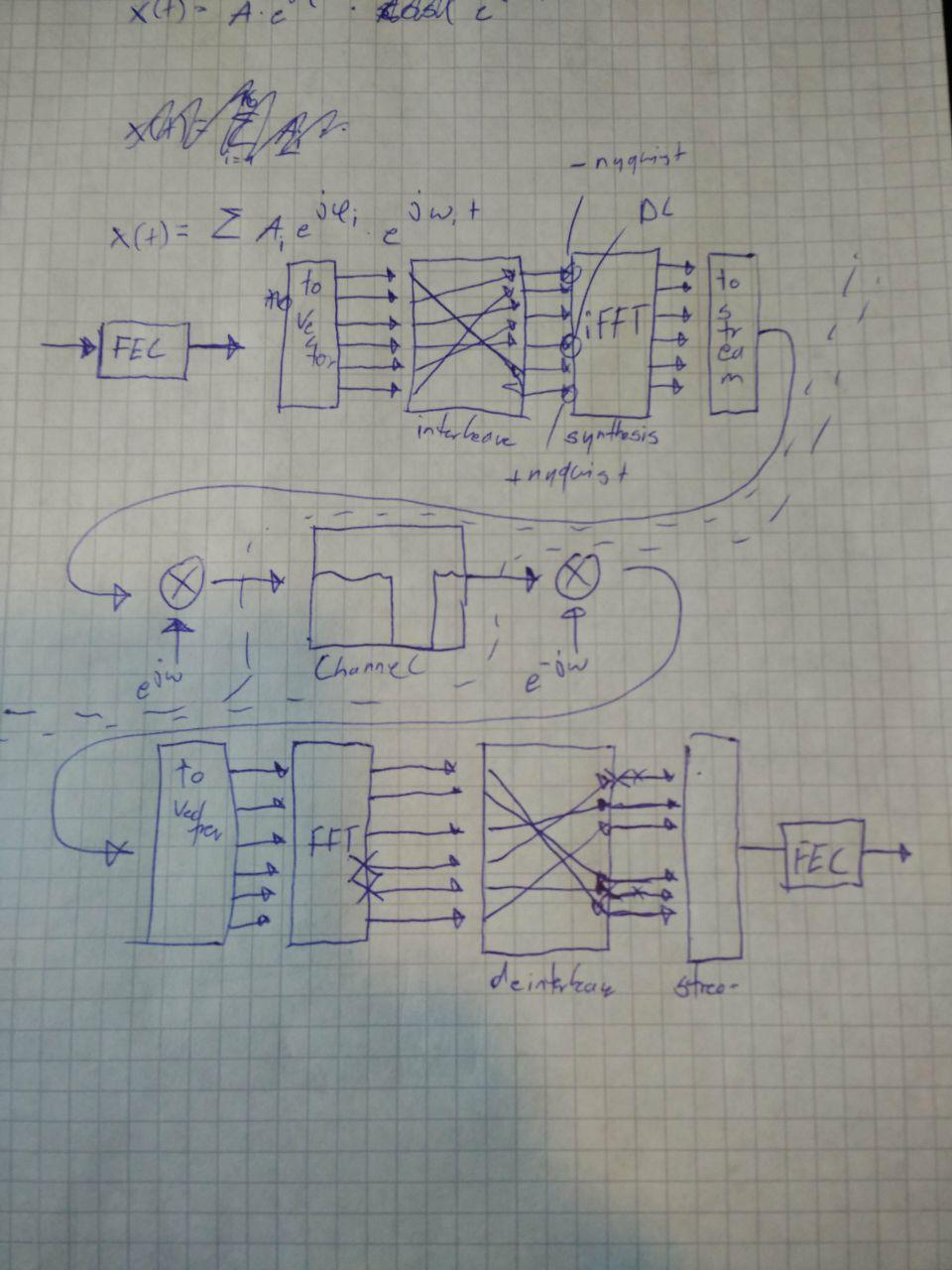
Dekodierstrecke besteht aus den inversen Operationen der Kodierstrecke:
Es ist also einleuchtend, dass man die Eingangsdaten am Sender beim Empfänger wieder raus fallen.
Fiesen Kanal einzeichnen
Kaputte Träger an der FFT einzeichnen
Die beeinflussten Träger sind benachbart. Das ist nicht gut. Deinterleaver und Interleaver ausfüllen.
FEC kann die kaputten Träger gut reparieren.
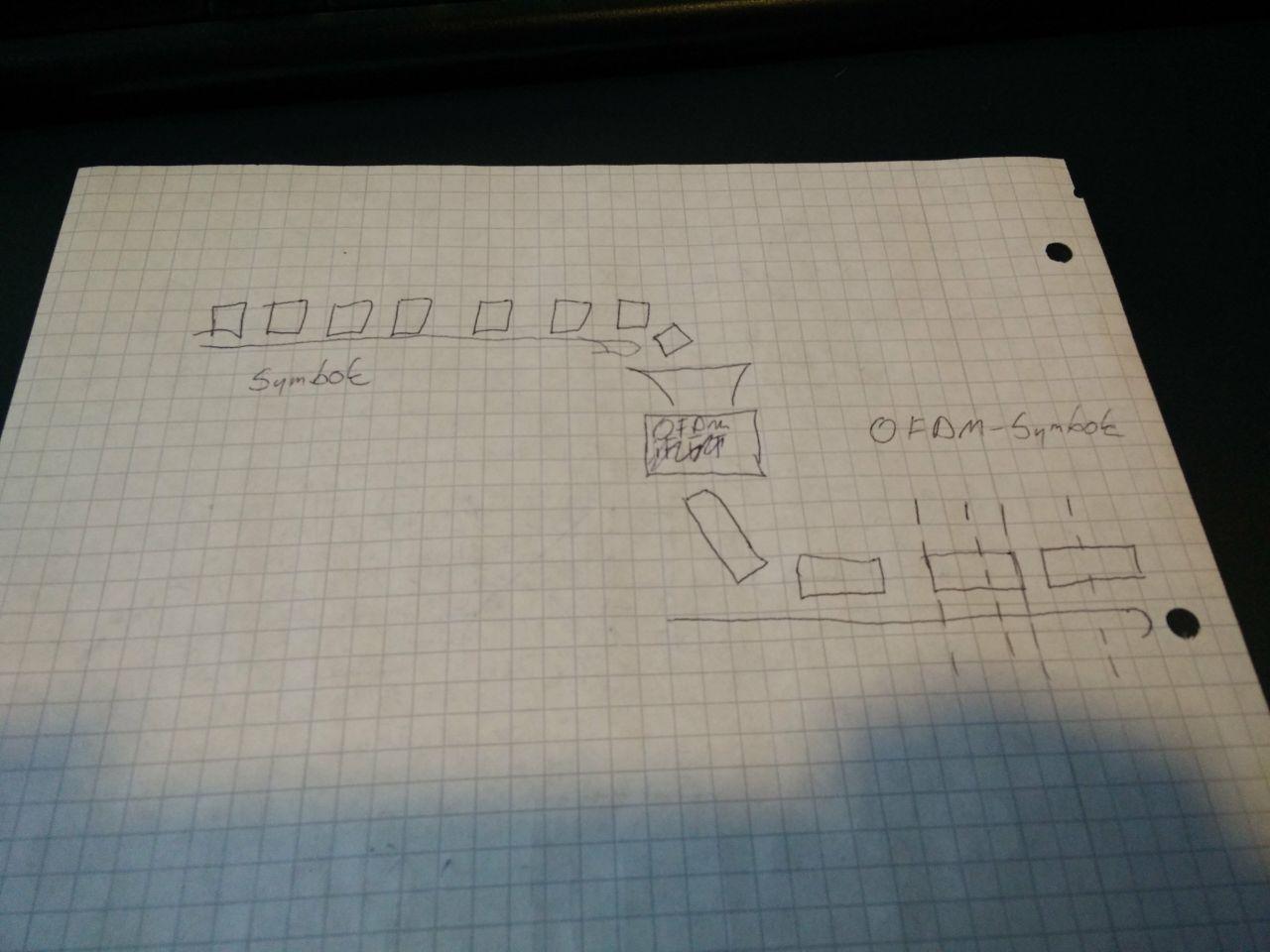
Eine Folge von Symbolen wird in eine Folge von OFDM-Symbolen umgesetzt
Ein OFDM Symbol besteht aus mehreren Symbolen
Rhetorische Frage: wer hat schon ein Waterfall diagram gesehen?
Waterfall diagram: Trägt auf der X-Achse die aktuelle Frequenzverteilung über einem Zeitpunkt auf der Y-Achse auf
Auf Vektorisieren und FFT nach dem Runtermischen verweisen - Sehr ähnlich dem Dekodierprozess bei OFDM
Deshalb werde ich zur Vorstellung der Anforderungen von OFDM auch ein ähnliches Frequenzverteilung-über-Zeit Diagramm nutzen
So sieht das Diagramm aus:
Die Kreuzungspunkte sind somit auch die optimalen Abtastpunkte um die kodierten Daten zu extrahieren
Das Diagramm zeigt eine perfekte Übertragung ohne Störeinflüsse
Was könnten Störeinflüsse sein? Z.B., wie erwähnt, ein Kanal mit nicht flachem Frequenzgang.
Der Kanal macht einige Unterträger unnutzbar
Durch Fehlerkorrektur aber behebbar
Was könnte noch passieren? Z.B. ein störender kurzer Burst durch ein anderes Protokoll oder ein Naturereignis
Burst macht einen Teil der Nachricht unnutzbar.
Braucht etwas cleverere Fehlerkorrektur als angemahlt aber ist an sich korrigierbar.
So weit läuft es ganz gut. Was könnte noch passieren? z.B. Frequenzoffset durch schlechte Taktquellen oder Doppler-Shift
Das Signal ist rekt. Alle Träger sind betroffen. Die FEC hilft nicht mehr viel.
Das liegt daran, dass wir jetzt zwischen Trägern abtasten. Und die Messung somit eine Kombination ist.
Was passiert bei einem Offset im Zeitbereich?
Auch bei Zeitoffset geht alles kaputt.
Auf Tafel zeigen was passiert
Es wird eine Mischung aus zwei aufeinanderfolgenden OFDM-Symbolen betrachtet.
Das illustriert, das Synchronisation nötig ist.
In echten Implentationen ist der Effekt deutlich weniger drastisch durch den Einsatz von Cyclic-Prefixes. Für den dramatischen Effekt werden die aber ersteinmal ignoriert.
Wie lässt sich die Synchronisation umsetzen?
Erster Ansatz: Am Empfänger Signalleistung untersuchen und daran entscheiden wann ein Frame anfängt.
Damit schafft man schon mal etwas zeitliche Synchronisation.
Ähnlich wird es z.B. in DAB+ gemacht.
Hat aber Nachteile:
Gehts das besser?
Ja. Z.b. mit dem 1997 vorgestellten Verfahren von Schmidl & Cox.
Dabei wird eine, erstmal irgendwie geartete, Sequenz zwei mal direkt nacheinander gesendet.
Im weiteren Verlauf wird angenommen, dass die Länge der Sequenz der halben OFDM-Symbollänge entspricht. Insgesamt ist die Preamble also eine OFDM-Symbollänge lang.
Zur Detektion wird das Eingangssignal um die Länge der Sequenz verzögert und konjugiert komplex mit dem unverzögerten Signal multipliziert.
Der Ausgang der Multiplikation wird über eine Sequenzlänge gemittelt.
Um das Ergebnis zu erzeugen wird also ein Fenster über den Ausgang der Multiplikation geschoben wild gestikulieren.
Am Ausgang ergibt das, auch bei hohem Rauschniveau, einen sehr deutlichen Peak in der Amplitude.
Die Phase können wir erst einmal ignorieren.
Dieser Peak lässt sich sehr schön zur Synchronisation detektieren.
Warum funktioniert das so schön? - Mathematik
Für die erste Betrachtung besteht das Eingangssignal x aus der Synchronisationssequenz und Rauschen.
Die Formel beschreibt die selben Operationen wie das Blockdiagram.
Es wird das verzögerte Signal konjugiert und mit dem unverzögerten Signal multipliziert. Das Ergebnis wird über die Länge der Sequenz (ein halbes ODFM-Symbol, deshalb N/2) gemittelt.
Wenn man das Eingangssignal zerlegt fällt auf, dass die Sequenz verzögert um N/2 wieder die Sequenz ist - so ist es ausgelegt.
Wenn man annimmt, dass das Rauschen weder mit der Sequenz korreliert noch mit seinem verzögerten selbst kann man davon ausgehen, dass es sich rausmittelt wenn N groß genug ist.
Der Ausgang, wenn das Fenster genau über der Sequenz liegt, entspricht der mittleren Leistung der Synchronisationssequenz.
Der Ausgangswert hängt linear davon ab wie viel von der Sequenz im Fenster liegt.
Nochmal zeigen, dass die Flanken rechteckig ansteigen
Warum ist auf dem Bild eigentlich die Phase mit abgebildet? Ist die zu was gut?
Vielleicht.
Rechnen wir durch was passiert wenn statt Rauschen ein Frequenzoffset als Störgröße eingeht.
Auf delta f und i zeigen das Signal und das verzögerte Signal sind jetzt mit einer zeitlich veränderlichen Phasendrehung belegt.
Durch die Konjugation sind die Drehrichtungen jeweils umgekeht.
Multipliziert man geht die Zeitabhängigkeit verloren und die Phasendrehung kann aus der Summe gezogen werden.
Der Phasenwinkel am Ausgang ist also vom Frequenz-offset, der Sampling frequenz und der Länge der S&C Sequenz abhängig.
Der tatsächliche Verlauf kann z.B. so aussehen.
Der Absolutwert bleibt unverändert. Die Phase, wenn das Fenster über der Sequenz liegt wird ungleich 0.
Der Frequenzunterschied lässt sich jetzt einfach durch Umformung berechnen.
Als Folge lässt sich jetzt der anfangs gezeigt Effekt eines Frequenzoffsets (alle Carrier gehen kaputt) durch mischen mit der Differenzfrequenz kompensieren.
Es kann sein, dass jetzt Träger außerhalb des aufgenommenen Frequenzbereichs liegen. Daran lässt sich nichts ändern.
Das war ganz interessant, aber an sich nichts neues.
Wir kommen jetzt dem konstruktiven Teil der Arbeit näher.
Vorher aber eine Vorstellung von GnuRadio
GnuRadio ist ein Software Framework zum schreiben von und eine Bibliothek an Digitalen Signalverarbeitungsmodulen.
Viele interessante Module sind bereits enthalten
Insgesamt also ein Tool um die Echtzeitverarbeitung von digitalen Signalen zu vereinfachen und zu vereinheitlichen
Erster und oft einziger Berührungspunkt neuer Nutzer mit GnuRadio ist der GnuRadio Companion
Hier können bereits vorhandene Blöcke grafisch zu Verarbeitungsketten verbunden werden.
Im Bild ist z.B. der bisher besprochene Teil des Schmidl & Cox Verfahrens implementiert inklusive Ausgabe auf dem Bildschirm
Es gibt aber auch weitere Möglichkeiten GnuRadio zu verwenden.
Z.B. können Blöcke und Programme in Python implementiert werden. Das gibt mehr Flexibilität, weil man nicht nur auf die bereits existierenden Blöcke zurückgreifen kann.
Dafür ist das direkte Skripten aber auch weniger intuitiv.
Wenn man mehr performance will kann man Blöcke auch direkt in C++ implementieren. Den Vorsprung in Rechengeschwindigkeit erkauft man sich dann allerding mit einer längeren Entwicklungs/Debug Zeit.
Bleibt man beim skripten in Python werden einem wahrscheinlich keine Speicherzugriffsfehler oder Memory Leaks begegnen. … Bei C++ sieht das anders aus.
Kommen wir zum spannenden Teil:
Was haben das Schmidl & Cox Intro und die Vorstellung von GnuRadio miteinander zu tun?
Das zu lösende Problem war, dass Schmidl & Cox, wenn es grafisch aus diskreten Blöcken implementiert wird zu langsam auf normalen Desktops ist um in Echtzeit WiFi frames zu detektieren.
Ziel war deshalb weite Teile in einen einzigen Block zu integrieren und diesen so weit zu optimieren, dass er das gesetzte Geschwindigkeitsziel erfüllt.
Resultat waren insbesondere die drei markierten Blöcke.
Für maximale Performance hätte man die Blöcke auch noch weiter integrieren könne.
Habe ich nicht gemacht, weil die Zwischenergebnisse aus verschiedenen Gründen interessant sein können, weil es Sinn machen kann einige der Blöcke ohne die anderen zu betreiben, und weil es Sinn machen kann Blöcke zu ersetzen
Wenn die drei Blöcke zusammenspielen fügen sie einen Tag an jede detektierte Schmidl & Cox Sequenz an.
Der Tag ist eine Markierung, die von späteren Blöcken genutzt werden kann. Z.b. um eine Dekodierung zu starten.
Der Tag enthält z.B. Informationen über Amplitude und Phase des S&C Peaks. Dadurch können später auch Frequenzoffsets kompensiert werden.
Der erste Block führt das besprochene Schmidl & Cox verfahren durch und normiert das Ergebnis mit der mittleren Leistung des Einganssignals
Der zweite Block nutzt dieses Signal um einen Tag an den Zeitpunkt der maximalen Amplitude zu setzen.
Um zu verhindern, dass leichte Schwankungen zu sehr vielen aufeinanderfolgenden Tags führten sind zwei Hysteresepunkte anzugeben zwischen denen die Detektion stattfindet.
Der dritte Block kann genutzt werden um die Synchronisation im Zeitbereich exakter zu machen und zu verhindern, dass fremde Synchronisationssequenzen detektiert werden.
Er verschiebt die Position einkommender Tags auf die Position mit der höchsten Kreuzkorrelation mit einer abgespeicherten Preamble.
Was habe ich bisher gelern?
Unter welchen Bedingungen sollte man OFDM einsetzen? Wann nicht?
Was sind die Anforderungen, die für einen sinnvollen Einsatz von OFDM gegeben sein müssen?
Was macht OFDM für gewissen Einsatzzwecke untauglich? Warum nutzt man es nicht über nicht lineare Kanäle? Warum nutzt DVB-T OFDM aber DVB-S nicht?
Welche Größen müssen zwischen Sender und Empfänger synchronisiert werden?
Welche Verfahren gibt es?
In welchen Fällen macht es Sinn ein einfacheres Verfahren zu bevorzugen?
Welchen Einfluss hat der Abstand der Träger? Warum ist es relevant wie schnell sich Empfänger und Sender relativ zu einander bewegen dürfen sollen?
Wie funktioniert GnuRadio intern? Warum ist die Verwaltung der Samplepuffer so performant? Was ist zu beachten damit das so bleibt?
Wie lassen sich eigene Blöcke implementieren in C++ und Python?
Wie lassen sich die Blöcke beschleunigen indem SIMD Instructions moderner CPUs besser genutzt werden?
Die nächsten Schritte
Performance der Implementierung besser analysieren und vergleichen.
Arbeit abgeben + bestehen
Code aufräumen damit ich ihn anderen Leuten mit gutem Gewissen zur Nutzung geben kann.
Abschluss:
Alle bisherigen Ergebnisse sind online einsehbar und stehen unter offenen Lizenzen.
Nach Fragen fragen